Contents
- How DFS works
- DFS - Recursive implementation
- DFS - Iterative implementation (using Stack)
- Complexity Analysis
- Applications of DFS
DFS starts at a given source node and explores as far as possible along each branch before backtracking.
A visited set is maintained to avoid revisiting nodes, which would cause infinite loops in cyclic graphs.
Consider the below undirected graph:
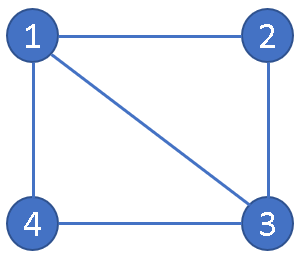
Starting DFS from node 1, the traversal proceeds as follows:
- Visit node 1, mark it visited. Explore its first unvisited neighbour.
- Continue going deeper — visiting each node and exploring its unvisited neighbours — until reaching a dead-end.
- Backtrack to the most recent node that still has unvisited neighbours.
- Repeat until all reachable nodes have been visited.
DFS uses a Stack data structure (LIFO). In the recursive approach, the call stack acts as the stack implicitly.
The recursive approach is the most natural way to implement DFS. We pass a Set of visited nodes
and for each unvisited neighbour of the current node, we recursively call DFS.
Algorithm steps:
- Mark the current node as visited.
- Process the current node (e.g. add to result list or print).
- For each neighbour of the current node, if it has not been visited yet, recursively call DFS on it.
import java.util.*;
public class GraphDFS {
// Adjacency list: node -> list of neighbouring nodes
private Map<Integer, List<Integer>> adjacencyList = new HashMap<>();
public void addEdge(int from, int to) {
adjacencyList.computeIfAbsent(from, k -> new ArrayList<>()).add(to);
adjacencyList.computeIfAbsent(to, k -> new ArrayList<>()).add(from); // undirected
}
/** Public entry point for recursive DFS */
public void dfsRecursive(int start) {
Set<Integer> visited = new HashSet<>();
dfsHelper(start, visited);
}
private void dfsHelper(int node, Set<Integer> visited) {
visited.add(node);
System.out.print(node + " "); // process the node
List<Integer> neighbours = adjacencyList.getOrDefault(node, Collections.emptyList());
for (int neighbour : neighbours) {
if (!visited.contains(neighbour)) {
dfsHelper(neighbour, visited);
}
}
}
}
Example usage:
GraphDFS graph = new GraphDFS();
graph.addEdge(1, 2);
graph.addEdge(1, 3);
graph.addEdge(2, 4);
graph.addEdge(3, 4);
graph.addEdge(4, 5);
graph.dfsRecursive(1);
// Possible output: 1 2 4 3 5
The iterative approach uses an explicit Deque as a stack to simulate the recursive call stack.
This avoids potential StackOverflowError for very deep or large graphs.
Algorithm steps:
- Push the start node onto the stack and mark it as visited.
- While the stack is not empty, pop a node from the top.
- Process the popped node.
- Push all unvisited neighbours of the popped node onto the stack, marking each as visited.
- Repeat until the stack is empty.
public void dfsIterative(int start) {
Set<Integer> visited = new HashSet<>();
Deque<Integer> stack = new ArrayDeque<>();
stack.push(start);
visited.add(start);
while (!stack.isEmpty()) {
int node = stack.pop();
System.out.print(node + " "); // process the node
List<Integer> neighbours = adjacencyList.getOrDefault(node, Collections.emptyList());
for (int neighbour : neighbours) {
if (!visited.contains(neighbour)) {
visited.add(neighbour);
stack.push(neighbour);
}
}
}
}
Mark nodes visited when they are pushed onto the stack, not when they are popped.
This prevents the same node from being pushed multiple times when it is a neighbour of several already-visited nodes.
-
Time complexity: O(V + E) — where V is the number of vertices and
E is the number of edges. Each vertex and each edge is visited at most once.
-
Space complexity: O(V) — the visited set and the call stack (or explicit stack)
can hold at most V nodes in the worst case (a linear chain graph).
- Cycle detection — detect whether a cycle exists in a directed or undirected graph.
- Topological sorting — order nodes in a Directed Acyclic Graph (DAG) based on dependencies.
- Finding connected components — identify all disconnected subgraphs.
- Solving maze and puzzle problems — explore all possible paths and backtrack on dead-ends.
- Strongly Connected Components (SCC) — used in Kosaraju's and Tarjan's algorithms.
- Path finding — determine if a path exists between two nodes.