A message containing letters from
-
"AAJF" with the grouping(1 1 10 6) -
"KJF" with the grouping(11 10 6)
Given a string
Output: 2
Explanation: "12" can be decoded as "AB" with mapping as 1->A and 2->B or "L" with mapping as 12->L.
Output: 3
Explanation: "226" can be decoded as "BBF" with mapping as 2->B, 2->B and 6->F or "VF" with mapping as 22->V and 6->F or "BZ" with maping as 2->B and 26->Z.
Output: 0
Explanation: "06" cannot be mapped to "F" because of the leading 0, if it was just 6 then it can be mapped to "F".
Contents
Solution 1 - using brute force approach Solution 2 - using DP memoization Solution 3 - using DP Bottom-Up approach using tabulation Solution 4 - using DP Bottom-Up approach memory optimized
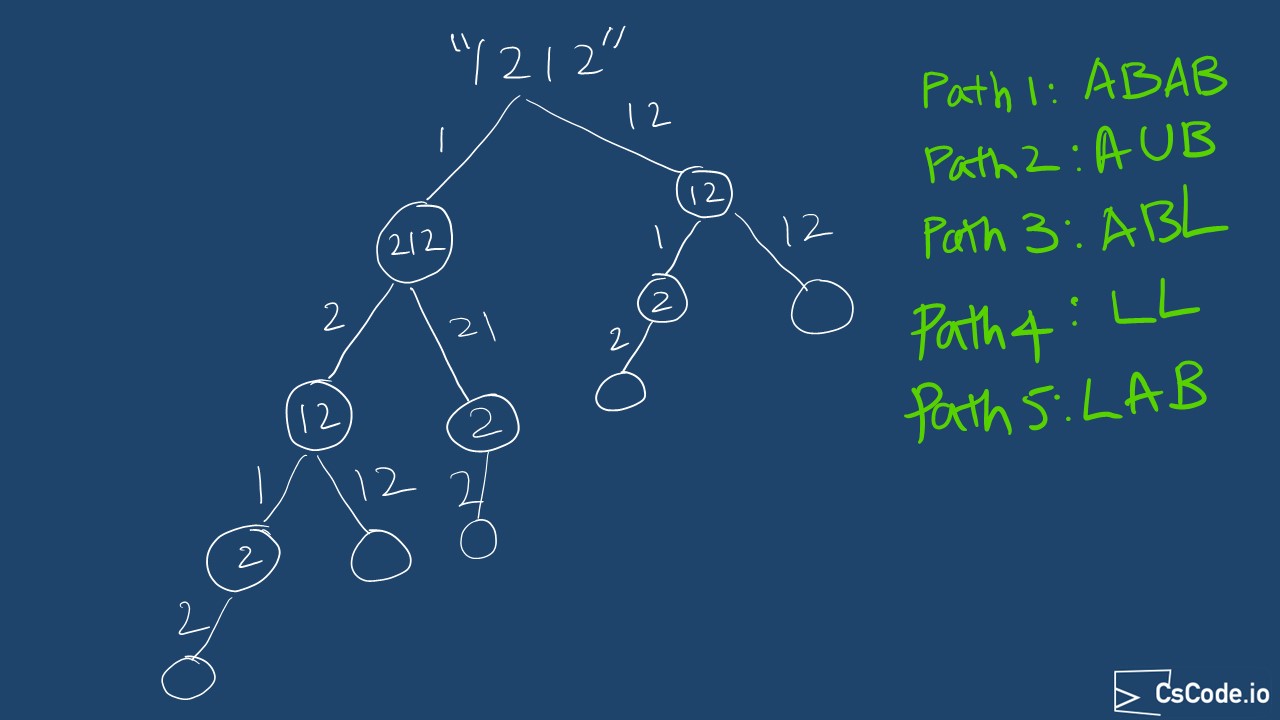
In this approach, we will generate all possible ways to decode the given input string. From every starting index of string we look at 1st indexed character and if it is valid, that is it should be a non zero character and 1st and 2nd characters together and if it is valid, that is it should be within the boundaries of two digit possible letters 10-26 (J-Z).
Say for example if the input string is "1212", you can see that from 1st digit
-
We will create a function
bruteForceApproach that takes input strings . -
Base cases are:
-
If the input string is
null or starts with letter'0' , then it is not possible to decode. So we will return0 . -
If the input string length is
0 or1 , then there is a way to decode it, so return1 .
-
If the input string is
-
Take the 1st character of the string, since it is a valid letter. For the remainder of string call the function
bruteForceApproach recursively. -
Then, check if we can take first two characters together and decode it, that means first two characters should be within the boundaries of 10-26.
We can take them if one of below conditions are satisfied.
-
If the 1st character is
'1' , meaning that we dont need to check for 2nd character because the maximum value that can be at 2nd character can be 9, so he possible values could be 10-19 and these are still within the boundaries of 10-26. -
If the 1st character is
'2' , then check for 2nd character and consider it only if it is between'0' and'6' to ensure it is within boundaries of 20-26.
-
If the 1st character is
-
If we are considering first two characters, then call the function
bruteForceApproach recursively for remainder of the string and increment the count of possible decode ways.
Complexity Analysis:
Time complexity: Above code runs in O(2n) time where
Space complexity: O(n) since we calling the function recursively, this is the stack memory.
From the above brute force approach, we can notice that there are some overlapping problems, such as sub problem with node
-
If we look at the decision tree diagram from above brute force aproach, highlighted sub problems are overlapping.
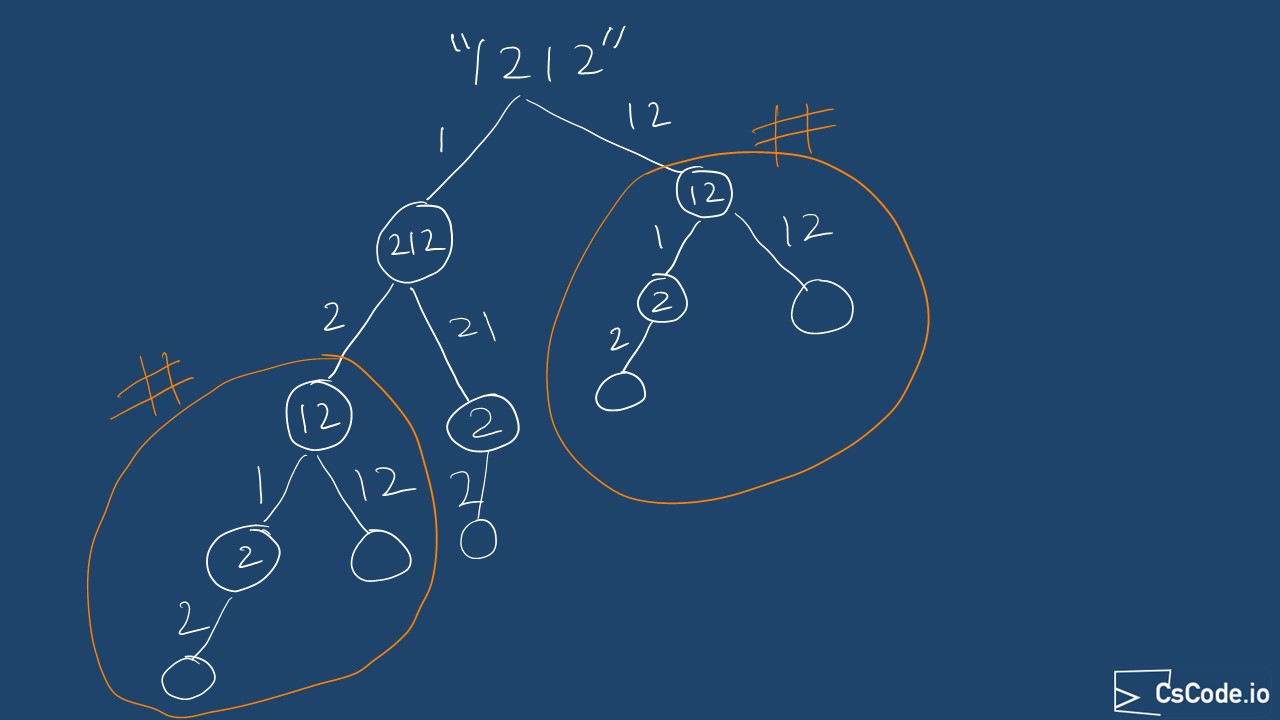
-
So, in this approach, we will be caching sub problem result into a
HashMap with input strings as key and its result as value. When a sub problem is repeated and found in cache, we will return it, otherwise we will call the function recursively and cache its result.
Complexity Analysis:
Time complexity: Above code runs in O(n) time where
Space complexity: O(n) for the cache we are maintaining and stack for recursive calls.
In this approach we will look at solving the problem using Dynamic programming using tabulation caching mechanism.
The time and memory complexity will be same as above solution using memoization,
but we can notice a pattern to improve memory complexity to constant in later solution.
In this solution, we are going to create a temporary array to cache the possible ways to decode at current index, and for the next subsequent index possibilities, use the cache built so far and continue exploring number of ways to decode. The main intution in this solution is:
-
When we are at index
i , if that element is1 or above , then consider it as a possibility as the value will be between1-9 and update the cache at current indexcache[i] with previous valuecache[i-1] from cache.
The reason why we do this is because when decoding is possible at current index element, then we need to update the cache at current index to indicate that decoding can continued to current index.cache[i] += cache[i-1]; -
Now, we also need to check whether decoding with two digits is possible or not. i.e. with previous element and current element.
If the previous value is
1 or if previous value is2 and current value is between0-6 , then there is a possibility to decode using two digits at current index. So, we will update the cache at current index by adding cache value fromi-2 index.
Consider an example with input string "1212":
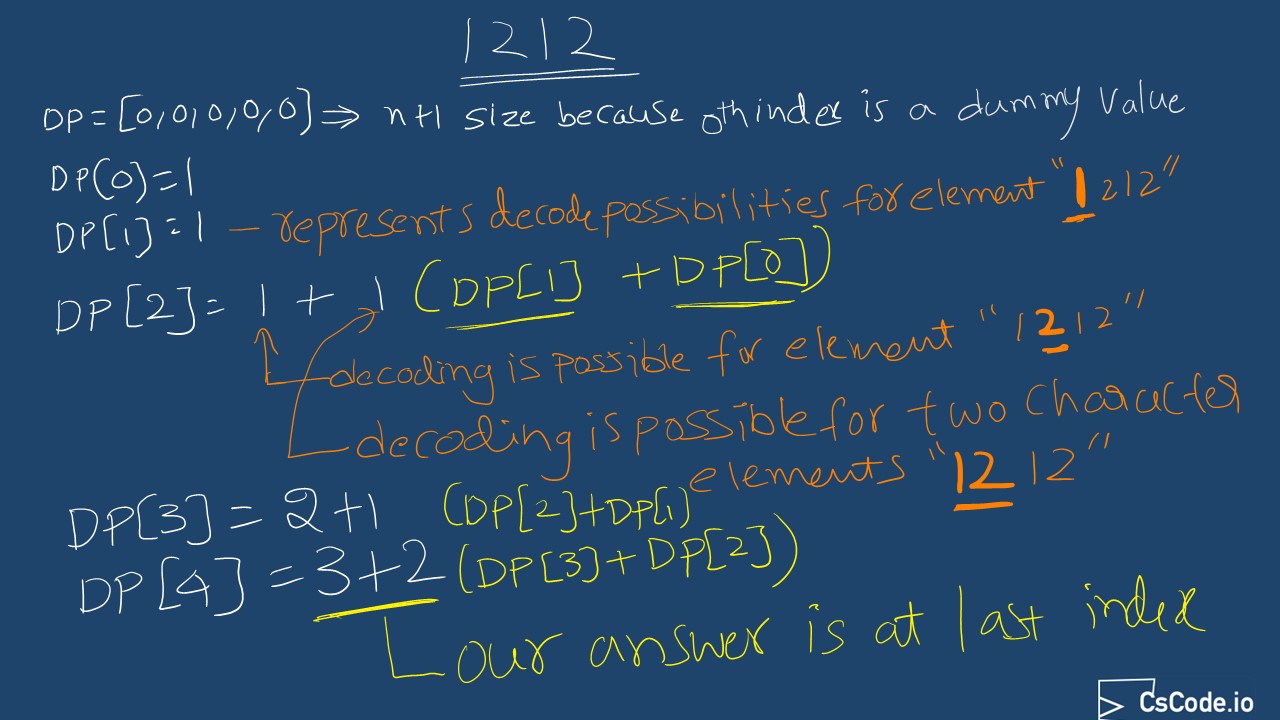
Complexity Analysis:
Time complexity: Above code runs in O(n) time where
Space complexity: O(n) for the cache we are maintaining.
If you observe above solution DP using tabulation we are maintaining a temporary array with size
Complexity Analysis:
Time complexity: Above code runs in O(n) time where
Space complexity: O(1) since we are maintaining previous two values.
Above implementations source code can be found at